Assessing the technical and organizational roadblocks to intelligent, end-to-end automation
Originally published on Medium

“We are drowning in information but starved for knowledge.” This is truer today than when John Naisbitt published his NYT #1 Bestseller, Megatrends, in 1982.
We all routinely make decisions based on imperfect and incomplete information. It’s not a preference, it’s just an operational reality. While ignorance may be bliss, it’s not a virtue. Timely, relevant facts allow humans and computers to make informed decisions and take optimized actions based on situational awareness.
With the advent of generative AI, there is growing understanding that domain knowledge is key to intelligent and even autonomous systems. The right information needs to be delivered to the right people and/or systems at the right time — Context-as-a-Service. However, real-time context is expensive.
It presumes that events can be evaluated as they happen and that the latest, related information can be queried, filtered, and processed efficiently in the moment. As part of this process, up to date data may have to be retrieved from local devices and remote systems. All of this has to happen between the blink of an eye (i.e., technically about 200 milliseconds) and what humans perceive as real-time (i.e., 1–2 seconds). Latency kills as decision windows close and information goes stale.
In my early research that led to founding EnterpriseWeb, I came across a clear-headed paper by Richard Hackathorn, “Real-time to Real-Value”. The paper presents a simple chart plotting time against value that nicely encapsulates the problem.
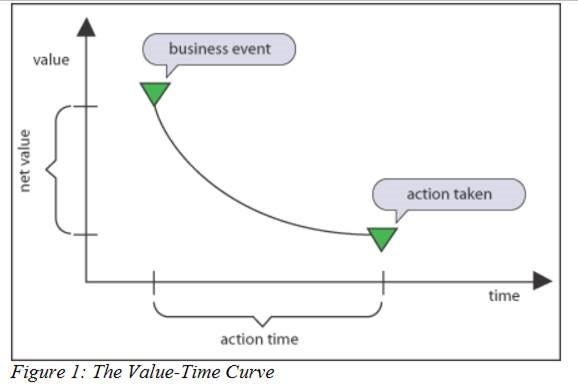
The closer you move to the event horizon, the higher the value. This is intuitive in human terms, but in 2004 when the paper was published the systems infrastructure was not in place to make that happen.
Twenty years later, most business applications still are not dynamic in this way, despite untold billions invested in data marts, data warehouses, data lakes and now semantic data lakehouses. The challenge is not just about I/O and compute, it’s about efficiently reasoning over information and contextualizing services in real-time, at scale. If this was an easy problem, it would have been addressed a long time ago.
A 2023 study, co-authored by renowned Knowledge Management expert, Tom Davenport, concluded that “Becoming data-driven and building a data culture remain aspirational objectives for most organizations — Just 23.9% of companies characterize themselves as data-driven…”.
That’s a problem. A prerequisite for successful Artificial Intelligence, including generative AI initiatives, is being data-driven and being data-driven requires that organizations have a knowledge graph, a wide and deep logical model of their operational domain, which supplies the elusive “context” to optimize behavior.
Realizing better data
The DIKW pyramid (Data, Information, Knowledge, Wisdom) is known to any data analysts worth their salt. In effect, it’s a maturity model for data modeling. Each step up the pyramid supports higher-level reasoning about data and its use:
- A domain defined with classes and entities raises data to information — the formalization and validation of data.
- Higher-level domain knowledge expressed in the form of graph concepts, types and policies (i.e., ontology) raises information to knowledge — the relationships support analysis and insights.
- When knowledge is operationalized to optimize action, we achieve wisdom, the top of the DIKW pyramid — understanding activity in its domain context.
The effort to model domains rigorously creates clear, consistent, coherent domain understanding not only for humans, but also for machines. This is why “better data” improves generative AI results, as well as AI/ML and analytics. So, the existence and scope of the knowledge graph is the first hurdle for realizing the intelligent enterprise; then you still need to make processing efficient, which is the second hurdle.
The cost of being real-time
It makes sense that the closer data is to a specific application domain, the more precise its meaning in that domain vernacular and the higher its utility. Conversely, when data is aggregated outside its domain context, it loses meaning, making it less useful. To application developers, this is the conceptual foundation of domain-driven design, the microservice “database per service” pattern, and data meshes of federated domains.
Data architects often dismiss these app-centric approaches as siloed, which is true, but the AppDev rationale is sound. Developers absolutely want data, but they need fast, efficient, secure access to relevant data that they can apply in context of a specific application. They work tactically within technical constraints and latency budgets (i.e., how much I/O, data processing, analysis and transformations can they practically perform in the span of a single human or system interaction). There is also a real financial cost to high-performance, low-latency, I/O and compute-intensive applications in terms of network bandwidth and resource consumption. So, context is expensive. From a practical perspective, developers generally throttle data processing for latency budgets and focus on local, application-specific parameters instead.
To Centralize or Federate
Historically, centralized solutions promoted by data architects, such as master data management, data marts, data warehouses, big data and even data lakes, haven’t exactly been unqualified successes. Generally, central data is historic (not operational), the processing is batch (not real-time), extracting relevant insights is difficult and time-consuming (inefficient). They are improving based on massive investments by hyperscalers and an emerging set of data cloud vendors, however, even proponents of next generation semantic data lakehouses acknowledge that it’s years, possibly a decade, before they could act as central operational databases for all business applications.
Likewise, federated approaches such as Data Mesh and Federated GraphQL, also struggle to deliver meaningful value. The problem is that they both lack useful application-level abstractions and are “read” only in nature.
In the case of Data Mesh, at best, implementations are lite catalogs of data products with limited and denormalized metadata requiring one-off manual integration. In an effort to avoid becoming a heavy-weight bus the Data Mesh architecture provides no shared models or tools, but as a result, it offers little utility and the movement is stalling.
GraphQL provides a simple static data model over pre-integrated data sources. It is a convenience for federated queries, but it can suffer inconsistent and unacceptable latencies based on performance and availability of the data sources. In addition, tight-coupling on the back-end makes the architecture brittle.
Conclusion
The tension between data architects and software developers is real, but data and code are two sides of the same coin. Everyone would like smarter, more responsive and adaptable processes. Siloed application data are simply a workaround to current real-world constraints, which in turn inhibit global visibility, end-to-end automation and centralized policy management. The barrier to the knowledge-driven organization is technical, not ideological.
EnterpriseWeb lowers the cost of context to enable the real-time digital business
It replaces static, tightly-coupled, vertically-integrated silos with a dynamic, loosely-coupled, horizontally-architected platform. The AI-enabled no-code platform simplifies and automates IT tasks to enable the rapid composition of intelligent business and infrastructure applications. It makes it easy for developers to leverage a common graph domain model and shared libraries across use-cases, while abstracting the inherent complexity of event-driven, distributed systems. The future is here.
See EnterpriseWeb in action
Secure Developer-centric Networking with CAMARA APIs
GraphOps for the Composable Telco
Intelligent Orchestration with Graphs: The Smart way to Coordinate SAP Services
Related Content:
Media coverage: Cloud, microservices, and data mess? Graph, ontology, and application fabric to the rescue
Graph conference talk: Graph-driven Orchestration
Contributed technical article: Graph Knowledge Base for Stateful Cloud-Native Applications
Whitepaper: Above the Clouds
Dave Duggal, founder and CEO, EnterpriseWeb
Dave has spent his career building & turning around companies. He anticipated the challenges of increasingly fragmented IT estate and founded EnterpriseWeb to enable highly-automated and agile business operations. Dave is the inventor of 20 US patents on complex distributed systems. He is a regular speaker at industry conferences and an occasional blogger.